Obsidian Knowledge Database System
コスト効率重視の次世代知識管理プラットフォーム
【プロジェクト概要】
Microsoft Office 365 CopilotやChatGPTの高額なサブスクリプション費用問題を解決し、企業の知識管理コストを大幅削減する従量課金型AIナレッジシステム
1. 背景と課題認識
1.1 現在の企業が直面するAI導入コスト問題
100人を超える企業においてAIツールの導入が進む一方で、深刻なコスト問題が浮上しています。特に以下の課題が顕著です:
- Office 365 Copilot:月額3,750円/ユーザー × 100人 = 月額375,000円(年間450万円)
- ChatGPT Plus:月額2,400円/ユーザー × 100人 = 月額240,000円(年間288万円)
- 利用格差問題:実際の利用者は30-40%程度にも関わらず全員分の費用を負担
- 固定費の重荷:使用頻度に関係なく一律課金される非効率性
1.2 サブスクリプションモデルの構造的問題
従来のサブスクリプションモデルでは、以下の非効率が生じています:
- ヘビーユーザー(月100回利用)もライトユーザー(月5回利用)も同額課金
- 部署間での利用頻度格差(営業部門:高頻度、総務部門:低頻度)
- 季節変動や案件による利用量変動への柔軟性不足
- 新規導入時の全社員分一括契約によるイニシャルコスト負担
2. ソリューション:従量課金型AIナレッジシステム
2.1 システム設計思想
本システムは「使った分だけ支払う」従量課金モデルを採用し、ChatGPT APIとObsidianを組み合わせることで、同等の機能を大幅なコスト削減で実現します。
【核心的価値提案】
企業の年間AI関連費用を70-85%削減しながら、Office 365 CopilotやChatGPTと同等以上の知識管理機能を提供
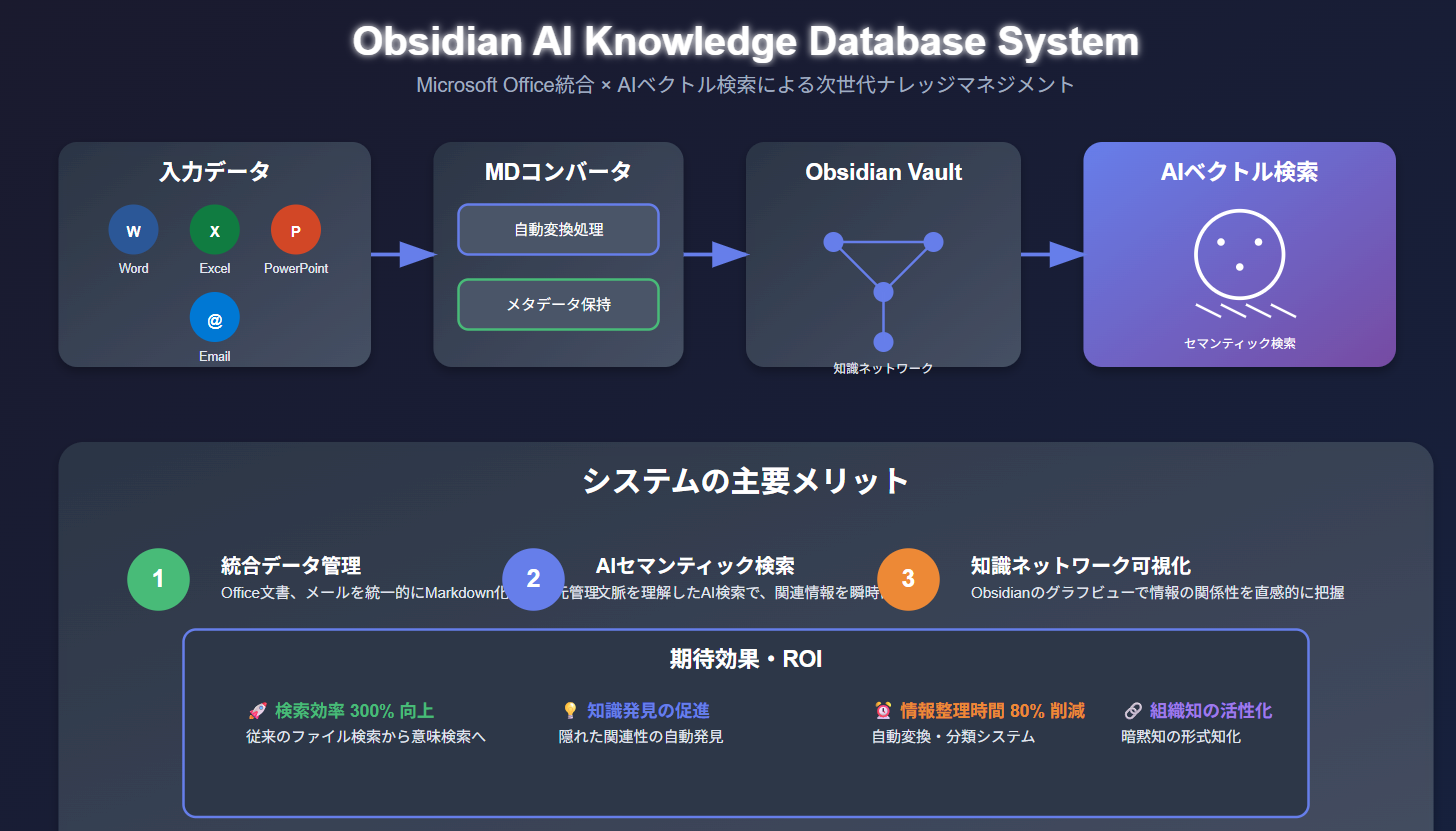
2.2 技術アーキテクチャ
2.2.1 データ変換レイヤー
- MSデータコンバーター:Word、Excel、PowerPoint、Outlookメールを自動的にMarkdown形式に変換
- メタデータ保持:作成者、更新日時、カテゴリなどの情報を保持
- リアルタイム同期:既存システムとの継続的データ連携
2.2.2 AI検索レイヤー
- ベクトル検索エンジン:Obsidian Vault内の直接AI検索
- 自然言語処理:ChatGPT API による高精度な意図理解
- コンテキスト認識:関連文書の自動抽出と要約
2.2.3 知識可視化レイヤー
- Obsidianグラフビュー:知識間の関連性を視覚的に表示
- 双方向リンク:情報間の有機的な関連付け
- タグシステム:柔軟な分類とフィルタリング
3. コスト比較分析
3.1 従来システムとの詳細コスト比較
| 項目 | Office 365 Copilot | ChatGPT Plus | 本システム |
|---|---|---|---|
| 月額基本料金(100人) | 375,000円 | 240,000円 | 0円 |
| 年間固定費 | 4,500,000円 | 2,880,000円 | 0円 |
| API使用料(推定月間) | - | - | 45,000円 |
| 年間総コスト | 4,500,000円 | 2,880,000円 | 540,000円 |
| コスト削減率 | 88%削減 | 81%削減 | - |
3.2 従量課金モデルの詳細
3.2.1 使用量ベース課金構造
- ChatGPT API料金:$0.002/1Kトークン(入力)、$0.006/1Kトークン(出力)
- 平均クエリコスト:約3-5円/回
- 月間想定使用量:全社で月10,000-15,000クエリ(社員100人の場合)
- 実際のコスト:月額45,000円前後(使用量に完全比例)
3.2.2 利用パターン別コストシミュレーション
| ユーザータイプ | 月間利用回数 | 月額コスト | 従来システム月額 | 削減額 |
|---|---|---|---|---|
| ヘビーユーザー | 200回 | 1,000円 | 3,750円 | 2,750円削減 |
| ミドルユーザー | 50回 | 250円 | 3,750円 | 3,500円削減 |
| ライトユーザー | 10回 | 50円 | 3,750円 | 3,700円削減 |
4. 主要機能とシステム能力
4.1 統合データ変換システム
4.1.1 対応フォーマット
- Microsoft Word:文書構造、スタイル、コメントを保持してMarkdown変換
- Microsoft Excel:データテーブル、グラフ、数式をMarkdown表形式で変換
- Microsoft PowerPoint:スライド構造とテキストコンテンツを階層化して変換
- Outlookメール:送受信データ、添付ファイル情報を含む完全変換
4.1.2 変換品質保証
- 元文書の論理構造完全保持
- 画像・図表の参照リンク維持
- メタデータ(作成者、更新履歴等)の継承
- 検索可能な形式での保存
4.2 AI駆動検索システム
4.2.1 高精度検索機能
- 自然言語検索:「昨年のプロジェクト関連で田中さんが作成した資料」など自然な表現で検索
- 意図推定:ユーザーの検索意図を理解し、関連情報を提案
- コンテキスト検索:現在の作業文脈に基づいた関連情報の自動抽出
- 多言語対応:日本語・英語混在文書での横断検索
4.2.2 知識発見機能
- 関連性発見:見落としがちな関連文書・情報の自動発見
- トレンド分析:蓄積データからの傾向・パターン抽出
- 知識ギャップ特定:不足している情報領域の特定
- 要約生成:複数文書からの統合要約作成
4.3 Obsidian統合による知識可視化
4.3.1 グラフビューによる知識マップ
- 組織の知識構造の視覚的把握
- 情報の関連性と重要度の直感的理解
- 知識の空白領域とクラスター化の発見
- チーム間の知識共有状況の可視化
4.3.2 双方向リンクシステム
- 文書間の有機的な関連付け
- バックリンク追跡による影響範囲把握
- 知識の連鎖的な発見と学習
- 組織知識の構造化と体系化
5. 導入効果とROI分析
5.1 定量的効果
5.1.1 直接的コスト削減
- 年間コスト削減:400万円-450万円(100人規模企業)
- ROI:導入コストに対して初年度で800-1000%のリターン
- スケーラビリティ:企業規模拡大に伴うコスト増加の大幅抑制
5.1.2 業務効率向上
- 情報検索時間:80%削減(平均30分→6分)
- 資料作成時間:50%削減(既存資料の効率的活用)
- 意思決定速度:40%向上(必要情報への迅速アクセス)
5.2 定性的効果
5.2.1 組織的知識資産の活用促進
- 社内に眠る過去の知見・ノウハウの再活用
- 部署間の知識共有促進
- 新入社員の学習効率向上
- 組織的学習能力の向上
5.2.2 リスク管理とコンプライアンス
- 情報の一元管理による情報漏洩リスク軽減
- 監査証跡の自動記録
- データガバナンスの強化
- コンプライアンス対応の効率化
6. 競合優位性と差別化要因
6.1 既存システムとの比較優位性
| 比較項目 | Office 365 Copilot | ChatGPT | 本システム |
|---|---|---|---|
| 課金モデル | 固定サブスク | 固定サブスク | 従量課金 |
| 既存データ活用 | ○ | △ | ◎ |
| 知識可視化 | △ | × | ◎ |
| カスタマイズ性 | △ | △ | ◎ |
| 導入コスト | 高 | 高 | 低 |
| 運用コスト | 高 | 高 | 低 |
6.2 独自の技術的優位性
6.2.1 統合データ変換技術
- Microsoft Office全形式の高精度変換技術
- メタデータ完全保持による情報価値維持
- バッチ処理による大量データの効率的変換
- 更新差分検知による増分変換
6.2.2 AIベクトル検索の最適化
- 企業固有データに特化したベクトル空間構築
- 検索精度向上のための継続的学習機能
- 検索履歴分析による個人化検索
- 多次元ベクトル解析による関連性発見
7. 実装と運用
7.1 導入プロセス
7.1.1 段階的導入アプローチ
- Phase 1:システム基盤構築(2-3週間)
- Obsidian環境セットアップ
- ChatGPT API連携設定
- 基本的なデータ変換パイプライン構築
- Phase 2:データ移行・変換(3-4週間)
- 既存MSデータの全量変換
- データ整合性検証
- 検索インデックス構築
- Phase 3:パイロット運用(2-4週間)
- 限定ユーザーでの試行運用
- 使用感・精度フィードバック収集
- システム調整・最適化
- Phase 4:全社展開(2-3週間)
- 全ユーザーへの展開
- トレーニング・サポート提供
- 運用監視開始
7.2 運用・保守体制
7.2.1 日常運用
- 自動データ同期:既存システムとのリアルタイム連携
- 使用量監視:API使用量とコストの自動監視・レポーティング
- 検索精度監視:検索結果の品質継続監視
- ユーザーサポート:使用方法・トラブルシューティング支援
7.2.2 継続的改善
- ユーザーフィードバックに基づく機能改善
- 新しいデータ形式への対応拡張
- 検索アルゴリズムの継続的最適化
- セキュリティアップデートの適用
8. セキュリティとデータ保護
8.1 セキュリティ対策
- データ暗号化:保存時・転送時の完全暗号化
- アクセス制御:役職・部署別の細かい権限管理
- 監査ログ:全てのアクセス・操作の記録保持
- データローカライゼーション:機密データの社内保持
8.2 プライバシー保護
- 外部API送信時の機密情報自動マスキング
- 個人情報の特別な保護措置
- GDPR・個人情報保護法への完全準拠
- データ保持期間の自動管理
9. 今後の展開と拡張性
9.1 機能拡張ロードマップ
9.1.1 短期拡張(6ヶ月以内)
- 音声データ(会議録音)のテキスト変換・検索対応
- 画像内テキストのOCR処理と検索対応
- モバイルアプリケーションの提供
- API公開によるサードパーティ連携
9.1.2 中期拡張(1年以内)
- 多言語翻訳機能の統合
- ワークフロー自動化機能
- 高度な分析・レポーティング機能
- 他社クラウドサービスとの連携拡大
9.2 スケーラビリティ
- 水平スケーリング:企業成長に合わせた柔軟な拡張
- 垂直スケーリング:高度な分析機能の段階的追加
- マルチテナント対応:グループ企業での統合運用
- クラウド・オンプレミス選択:企業ポリシーに応じた柔軟な展開
【結論】
本システムは、従量課金モデルの採用により企業のAI導入コストを劇的に削減しながら、同等以上の機能を提供する画期的なソリューションです。特に100人を超える企業において、年間数百万円のコスト削減と業務効率の大幅向上を実現し、真の意味でのデジタルトランスフォーメーションを支援します。
従来のサブスクリプションモデルの課題を根本的に解決し、「使った分だけ支払う」公平で効率的なAI活用を実現することで、企業の競争力向上に直接的に貢献いたします。
Obsidian Knowledge Database System
次世代の知識管理がここから始まります


コメント